
www.TestsTestsTests.com

IF Function Excel, SUMIF and COUNTIF in Excel Tutorial
Free Online Microsoft Excel 2010 Tutorial
Formulas & Functions in Excel
* What is the purpose of IF statements in Excel?
*
How to use IF in Excel
*
How to use COUNTIF in Excel
*
How to use SUMIF in Excel
IF functions in Excel allow you to create formulas based on true or false evaluations. The power of IF, SUMIF and COUNTIF creates dynamic worksheets that provides results based on data being entered, calculated and evaluated removing the manual task of analyzing a worksheet.
Test your Excel skills with the corresponding FREE Online Multiple Choice
IF, SUMIF and COUNTIF in Excel Test
* What is the purpose of IF statements in Excel?
You may have seen the IF function in Excel before and wondered how it works or tried to use it and gave up when it didn’t yield the results expected or you got the dreaded: Excel found an error in the formula you entered, message.
IF statements or functions in Excel allow you to evaluate data and return a value if the condition is met. Put in simple terms, an IF formula checks if a cell value is true or false based on specified conditions and then performs a specified action to return a value.
Using the IF function ensures that your data is dynamic and automates manual functions and calculations that are based on conditions.
In the screenshot example below, we want to divide the dogs into those who should receive the Junior dog food and those who should receive the Senior dog food, based on their ages. If a dog is older than 5 years, he should receive Senior dog food and 5 years and younger should receive Junior.
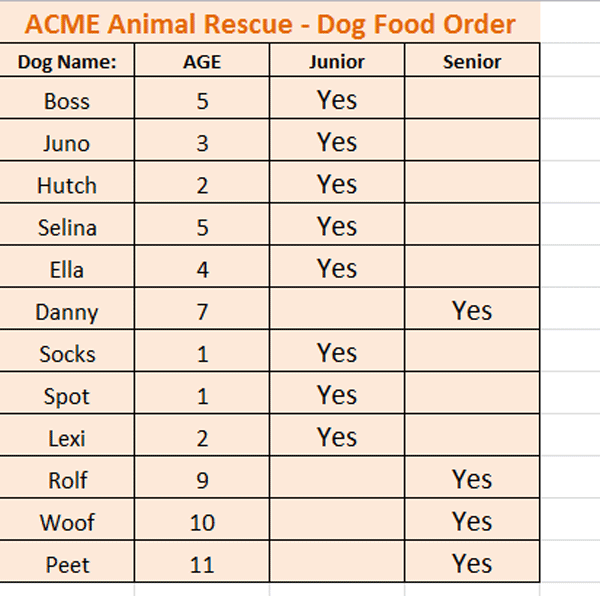
The logic for ascertaining which dog should receive Junior and which should receive Senior dogfood requires that the age of the dog is checked in the AGE column and then returns a “Yes” in the relevant Junior or Senior column.
The formula for achieving the above would be:
In the first cell of the Junior column: =IF(B3<=5,”Yes”,””). This formula is copied down in the column and the reference cell, B3, will change to B4, B5, etc.
This formula translates as: if the contents of the cell B3 contains a value that is less than or equal to 5, insert the word Yes in the cell containing the formula. If it is not less than or equal to 5, i.e. a number greater than 5, the cell should be left blank.
In the first cell of the Senior column: =IF(B3>5,”Yes”,””). This formula is copied down in the column and the reference cell, B3, will change to B4, B5, etc.
This formula translates as: if the contents of the cell B3 contains a value that is greater than 5, insert the word Yes in the cell containing the formula. If it is less than or equal to 5, the cell should be left blank.
By using an IF function, we instruct Excel to evaluate values and conditions and if they are met, return a desired value. The above is a very simple example for the use of IF statements, which will be investigated in further detail in the rest of this tutorial.
* How to Use IF in Excel
Imagine a parent saying to a child: if you clean your room then you can play computer games, else you will be grounded. The IF function in Excel works in exactly the same way.
The screenshot below represents the following scenario:
A sales person’s total sales for each quarter are detailed in columns labelled Q1, Q2, Q3 and Q4 and the Total column represents the sum of the sales for the four quarters. The company pays a bonus of $300 to each sales person who grossed more than $2,800 in sales and only $50 to all sales people who grossed less than $2,800.
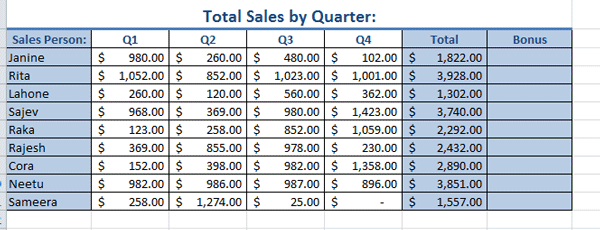
To evaluate which sales person should receive which bonus amount automatically in the Bonus column in the screenshot above, we could use the IF function.
The following steps detail how to use the IF function for this scenario:
1. Select the cell in which you wish the result to appear. In the above example, it would be the first open cell in the Bonus column.
2. Insert the IF function by typing:
=IF(
3. Excel will show the arguments for the IF function in a screen tip, as follows:
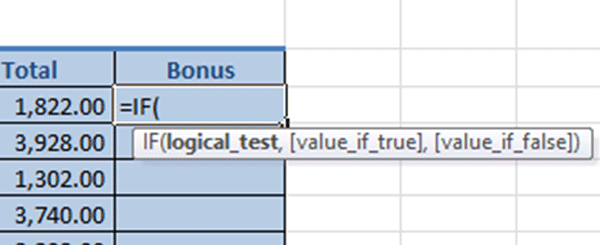
4. The logical test means the condition that needs to be met. In our example, the condition is that the amount in the cell in the Total column (F3) to the left of the selected cell (G3) must be evaluated as being more than, or equal to, $2,800.
To evaluate this, continue the formula as follows:
=IF(F3>=2800,
The symbols > and = evaluate the contents in cell F3 and check if they are greater than (>) or equal to (=) $2,800.
5. The next part of the formula instructs Excel as to what value to insert in the cell (G3) as a result if the condition is true. In our scenario, if the condition is true it means the sales person should receive a bonus of $300.
To instruct Excel to insert $300 into cell F3, continue the formula as follows:
=IF(F3>=2800, 300,
6. The final step is to instruct Excel what to do if the condition is not met, i.e. if the total sales amount is less than $2,800, to insert only $50 in cell F3.
To add this condition, complete the formula as follows:
=IF(F3>=2800,300,50)
7. Press the Enter key to complete the formula. Use the Fill Handle in the bottom right-hand corner of the cell to copy the formula down to all the relevant cells in the Bonus column.
The completed formula will look like this:
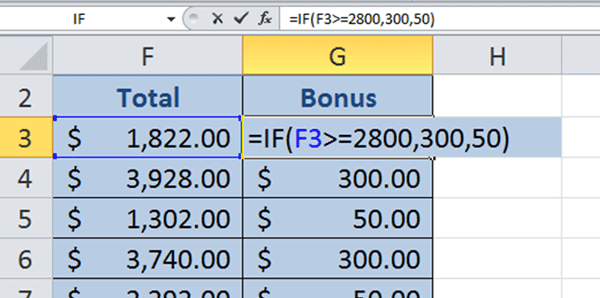
Should the value for the If True and If False arguments be text, enclose the words in inverted commas. For example: =IF(F3>=2800, “Yes”, “No”) will insert the word Yes into the Bonus column if the amount is more than or equal to $2,800 and the word No, if the amount is less than $2,800.
* How to use COUNTIF in Excel
The COUNTIF function does exactly what its’ name implies: count cell entries based on specific criteria being met. For example, you may want to count how many employees earn over a certain amount or only count how many students responded positively to an invite to the half-term dance.
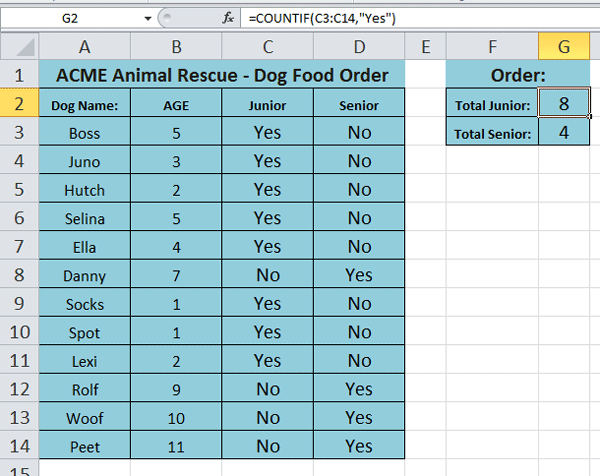
In the example in the screenshot below, the Order totals for Junior and Senior dogs counts the number of instances of Yes the Junior and Senior columns respectively.
The syntax for using COUNTIF in the example below is:
In cell G2: =COUNTIF(C3:C14,“Yes”)
In cell G3: =COUNTIF(D3:D14,”Yes”)
The arguments for COUNTIF is: =COUNTIF(range, criteria)
The range comprises the cells which contain the nonblank cells you wish to count.
The criteria comprises the argument to be met for the nonblank cell(s) to be included in the count.
If the criteria contain text strings, it must always be enclosed in double quotation marks. If you wish to use symbols to evaluate values such as greater than, less than, equal to or not equal to, these must also be enclosed in double quotation marks.
For example, the formula: =COUNTIF(B3:B14, “<5”) will count all the instances of dogs that are younger than 5 years old. The result will be 6 (see example screenshot above).
If we entered the formula: =COUNTIF(B3:B14, “<=5”) it will count how many dogs are younger than or equal to 5 years old. The result will be 8 (see example screenshot above).
Another way of using COUNTIF is to insert a cell that contains the criteria for the formula to match. For example, =COUNTIF(C3:C14,C3) will count all the cells in the specified range (C3 to C14) which contents match that of cell C3.
To use COUNTIF:
1. Select the cell in which you wish the result for the COUNTIF function to appear.
2. Type an equal sign followed by the word COUNTIF and an open bracket:
=COUNTIF(
3. Select the cells which contain the values you wish to evaluate and count should they meet the necessary criteria and follow the range with a comma, for example:
=COUNTIF(A1:A12,
4. Now insert the criteria for the cells you wish to include in the count. This could be a cell that contains the value, a number, a value you wish to evaluate using greater than, equal to, etc or a word. Remember to follow the guidelines for inserting the different types of criteria detailed above. For example:
=COUNTIF(A1:A12, “<=10”)
5. You can insert one criteria and one range only. Close the bracket and press Enter on your keyboard to finalize the formula.
Translated into everyday language, the COUNTIF function will look like this:
=COUNTIF(the cells containing the values I want to check for criteria and count if they meet it, the criteria I want to find in the cells).
* How to use SUMIF in Excel
The SUMIF function works in much the same way as the COUNTIF function and has the similar syntax in the formula too. It allows you to specify which numbers to include in a sum based on criteria, but has an extra argument to specify which range to sum, which is optional.
Study the example in the screenshot below:
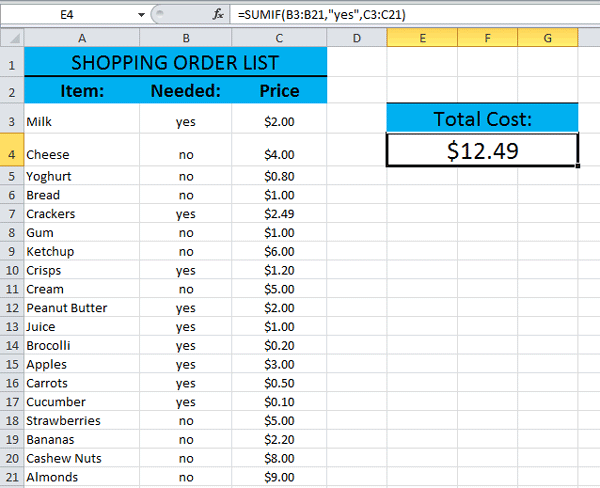
The selected cell (a merged cell), below the Total Cost heading in the screenshot above, contains the formula:
=SUMIF(B3:B21,”yes”,C3:C21)
The syntax for SUMIF is:
=SUMIF(range, criteria, [sum_range])
In the example above, cells B3 to B21 (the Needed column) is the range containing the value that the formula is evaluating. The next part of the formula, criteria, is the value you wish to find. In the example it is “yes”. Therefore the formula is searching cells B3 to B21 for the word yes. The last part of the formula, sum_range, is not always necessary. This is the range containing the values you want to add up (SUM) if the condition is met. In the example above that is the values contained in C3:C21.
Every time the formula finds the word yes in the B column, it includes the value contained in the corresponding cell in the C column in the sum. If you manually add up all the values preceded by yes in the example above, you will get to the same total as detailed below the Total Cost heading.
To use SUMIF:
1. Select the cell in which you wish the result for the SUMIF to appear.
2. Type an equal sign followed by the word SUMIF and an open bracket:
= SUMIF(
3. Select the cells which contain the values you wish to evaluate and/or sum if it meets the necessary criteria. Follow the range with a comma, for example:
= SUMIF(A1:A12,
4. Now insert the criteria for the cells you wish to include in the SUMIF. This could be a cell that contains the value, a number, a value you wish to evaluate using greater than, equal to or even a word. For example:
= SUMIF(A1:A12, “<10”
5. If the criteria range (A1:A12 in this example) contains the values you want to add together if it is less than 10, you can close the brackets and press the Enter key on your keyboard to finalize the formula.
HOWEVER:
If the criteria range DOES NOT include the values you wish to sum and only the criteria to evaluate, add a comma after the criteria, for example:
= SUMIF(A1:A12, “<10”,
Next insert the range that contains the values to sum. For example:
= SUMIF(A1:A12, “<10”,B1:B12)
This will add up all the values in cells B1 to B12 if the corresponding cells in A1 to A12 are less than 10. If the corresponding value is greater than 10 in A1 to A12, the formula will not add up those corresponding values in B1 to B12.
In everyday language, the SUMIF function can be translated as follows:
=SUMIF(the cells containing the values that I want to evaluate to see if it meets specified criteria, the specified criteria and finally, the actual cells I want to add together if the criteria is met).
Woohoo! Now that you have done the tutorial:
Test your Excel skills with the corresponding FREE Online Multiple Choice
IF, SUMIF and COUNTIF in Excel Test
TRY THE NEXT TUTORIAL: Nested IF in Excel SUMIFs & COUNTIFs
Advanced Excel Functions Tutorial
TRY THE NEXT TEST: Nested IF in Excel SUMIFs & COUNTIFs
Advanced Excel Functions Test
* More from TestsTestsTests.com
